You have almost certainly heard about Machine Learning lately, and that is because this scientific discipline is being applied to more and more fields. This is due to two main reasons: great technological progress, especially the computing capacity, and the large amount of data that we currently have.
Machine Learning is a branch of artificial intelligence that focuses on the study of algorithms to create predictive models.
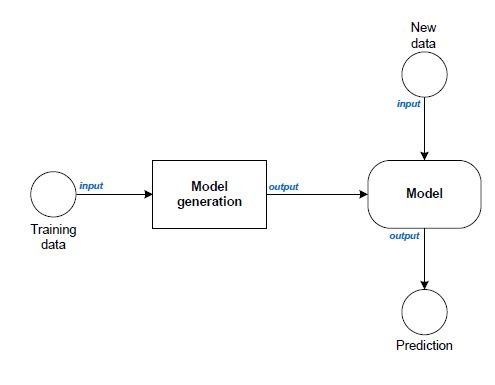
It essentially works as follows: from some training data, a mathematical model is generated based on disciplines such as statistics and algebra. New data are subsequently introduced to this model to make the prediction, as shown in Illustration 2.
In the model training process, input data are divided into two or three sets. One of them is allocated to the training itself, which is the biggest set. The second is used to test the model and the third for validation purposes. The latter is optional as it depends on the amount of data we have. As a general rule, it is recommended that more data should be assigned to training than to testing. In the event of using an extra set for validation, the test set is usually divided and a part is assigned to the latter set. For example, if 60% is allocated to training and 40% to testing, the latter percentage is divided with the following distribution: 20% for testing and the remaining 20% for validation.
There is a great variety of algorithms, which are grouped into three main categories depending on the type of learning that takes place in the creation of the mathematical model. These are explained below.
1. Supervised Learning
In supervised learning, a predictive mathematical model is created by applying certain algorithms to a set of data, which already have their corresponding category. That is to say, each element of the set has a label associated with it which defines the category this element corresponds to for the purpose of introducing unclassified data into the model and ensuring that this one provides us with the category to which they belong.
The generation process is based on classifying the elements of the training set and comparing the result with the label associated with each element. This process is carried out iteratively to adjust the predictive model.
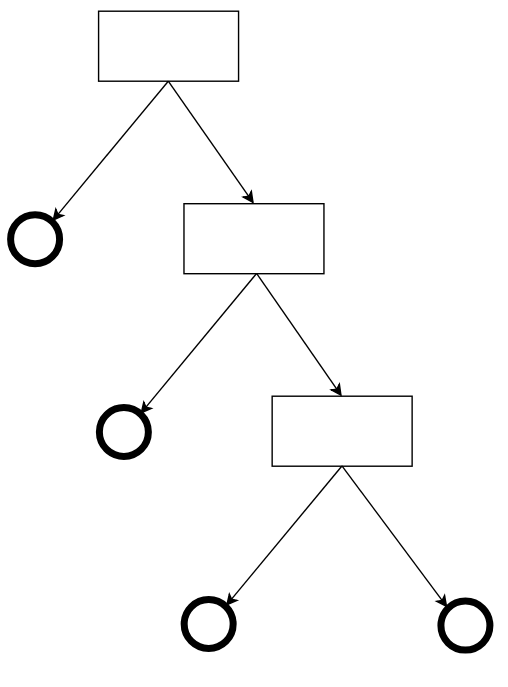
One of the best-known supervised learning algorithms is based on Decision Trees, which use the “divide-and-conquer” technique to classify input data, taking into account the characteristics/properties of the data. This algorithm in particular is based on probability, using the entropy value, which reflects the level of uncertainty or disorder, showing which of the data attributes are most relevant in the decision-making process. This value is between 0 and 1.
2. Unsupervised Learning
In contrast to the previous category, in unsupervised learning, the training data set used does not have labels. Therefore, these algorithms only take into account the attributes/characteristics of these data. Within this category, the best-known algorithms are based on the clustering process.
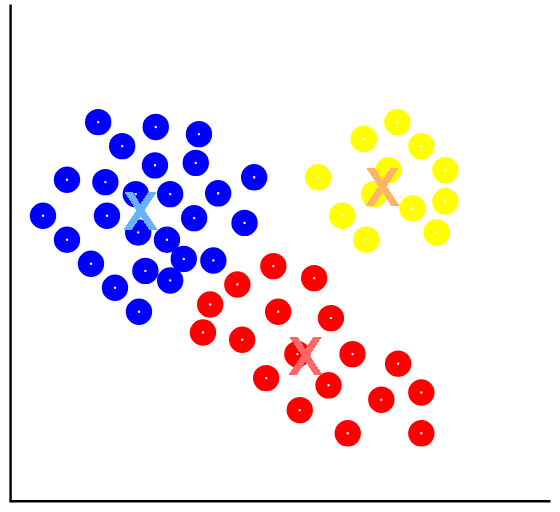
An example of an algorithm belonging to this type of learning is the so-called K-Means, whose purpose is to group data into k groups according to their characteristics/attributes. It is based on the use of quadratic distance.
The algorithm is divided into four phases:
-K centres are established in the vector space in which it is working and these can be selected in different ways, one of them being at random.
-Once the centres are defined, the data are associated with the centre with the closest average.
-The algorithm then recalculates the position of the centres with respect to the data associated with each centre.
-Phases 2 and 3 are repeated iteratively, as many times as configured. Ideally, the number of repetitions must be set until convergence is reached.

3. Reinforcement Learning
It includes the algorithms that most resemble human learning, since it is based on trial and error. To achieve this behaviour, a reward/punishment function is implemented. Training data are labelled using a mathematical function that can be discrete or linear. In this type of learning, the decision-making process is more important to reach the target than the solution itself.
That is to say, after each decision made by the algorithm until it reaches the target, a reward is given, the value of which depends on the correctness of the decision made.
After finding the solution, the quality of the decisions taken is evaluated based on the set of rewards/punishments obtained during the process of solving the problem.
The problems to which this type of algorithm is applied have two main components:
-An agent, which represents the entity that performs the actions/decisions, in this case the algorithm.
-And an environment, which represents the context of the problem.
In short, this type of learning is intended to optimise the process of finding the solution to a particular problem.
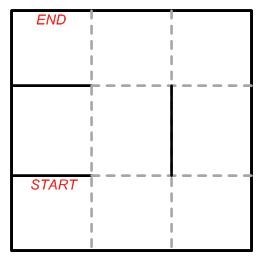
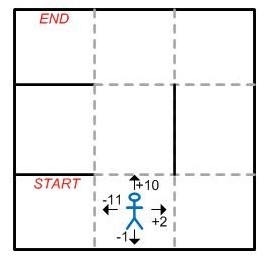
An example of the application of this type of learning can be found in maze-solving algorithms. In this particular case, the context is the maze itself, which has attributes such as distribution, and the agent is the algorithm that is applied to solve it.
In each step, the agent is rewarded or punished with a value that accumulates. In the event that it advances against a wall, it will obtain a negative value as “punishment”, and in the event that it advances toward a path, it will be given a positive value that will vary depending on how good that path is, as shown in Illustration 7.
The algorithm, after reaching the end, will have the accumulation of rewards/punishments and this value will give you the information as to how good the path it has taken is. Training is considered complete when you have found the optimal path, that is, the path in which the accumulated reward value is the highest.
Overfitting and Underfitting
To conclude the article, we would like to mention two problematic situations that can occur during and after model training.
The first problem we will deal with is called Overfitting. It occurs when the model fits so closely with the training data that when new data are entered for a particular category, if they do not have exactly the same characteristics as the training data belonging to that same category, they will not be classified correctly.
For example, in an animal classification algorithm, if your training data only include characteristics of a certain dog and this problem occurs, when new data relating to a dog with characteristics different from the training are entered into the model, it will not be recognised as a dog.
And the second case is called Underfitting, which is the opposite of the previous one. It happens when the model fits so poorly that it is unable to make an acceptable classification/prediction, even though the new data have characteristics that are very similar to the data used during training.
If you are interested in knowing more about this scientific discipline, stay tuned! In upcoming articles we will delve a little deeper into the world of Machine Learning.

